Geo-Rails Part 8: ZCTA Lookup, A Worked Example
georails
This week we'll put together what we've covered so far in this series by implementing a simple but usable service: looking up the Zip Code Tabulation Area (ZCTA) for a location. This is an actual task I had to do for my job at Pirq, and while I will pare it down for this article, we'll go through some of the actual trade-offs and optimization decisions I made in our implementation.
In this article, we will cover:
- The goals for the service, and what is a ZCTA anyway
- Obtaining ZCTA data from the U.S. Census
- Developing our own ZCTA database
- Querying the database
- Improving performance using polygon segmentation
This is part 8 of my continuing series of articles on geospatial programming in Ruby and Rails. For a list of the other installments, please visit http://daniel-azuma.com/articles/georails.
ZCT-what?
At Pirq, we do a lot of geospatial analysis. One task we have to perform fairly frequently is to group data into neighborhoods for demographic and spatial analysis.
Now, mapping coordinates to neighborhoods is a more challenging task than you might suspect. There is no "official" database, and boundaries on the ground are often imprecise and subject to rapidly evolving local information. One way that you could go about it is to define neighborhoods as zip codes or clusters of zip codes, but this carries its own challenges because (perhaps counter-intuitively) zip code "boundaries" are not well-defined either. Zip codes are defined by postal routes, and don't necessarily correspond to or respect any other boundary information, including even city and state boundaries. (For further discussion, see the US Census position on zip codes at http://www.census.gov/geo/www/tiger/tigermap.html#ZIP.)
There are two different ways of tackling the problem of mapping neighborhoods or zip codes. One is to use a (paid) service to do the local heavy lifting---curating and cleaning the data, and tracking and applying local knowledge---for you. I generally recommend Maponics for this task, but there are a variety of services available. Alternatively, if you're content with approximate data, and/or you have more direct access to some amount of local knowledge, you can build your own database using Zip Code Tabulation Areas (ZCTA).
ZCTA (pronounced "zik-tuh") is a system created by the US Census to address the zip code problem. The idea is this. Sometimes you need to look up the actual zip code for a location for reasons related to postal delivery. In such cases you will need to work directly with the US Postal Service or a third-party curator like Maponics. But other times you don't necessarily need the actual zip code, but you just want to use something like a zip code as a convenient unit of delineation for geo-analysis---for example, to approximate neighborhood boundaries. In this latter case, it doesn't matter that the zip code itself isn't always 100% accurate. Rather, what's important is that the boundaries are stable and make geographic and demographic sense. ZCTA is designed for this latter case.
Each ZCTA is a collection of US Census blocks for which, at the time of the census, the addresses fell largely if not completely within a particular zip code. Because ZCTAs are made up of Census blocks, they are well-defined, stable, and statistically useful. And usually, they approximate the actual zip code boundaries fairly well.
For this article, we'll build a simple ZCTA lookup tool: one that will let you query a location (latitude and longitude) for which ZCTA contains it.
Setting up our database to hold ZCTA data
I'll assume we've set up a Rails project and a PostGIS database as covered in part 2. Let's start by creating a model for the ZCTA data. For now we'll just create a simple table capable of mapping geometry to ZCTA (zip code). You can of course modify this to add more fields.
% rails generate model Zcta zcta:integer region:polygonThis creates the following migration:
class CreateZctas < ActiveRecord::Migration
def change
create_table :zctas do |t|
t.integer :zcta
t.polygon :region
t.timestamps
end
end
end
Before we migrate, we'll do a few things here. First, we don't need those timestamps so we'll get rid of them. Second, we will want to do spatial queries against the :region column, so we'll create a spatial index on that column, as we covered in part 6.
Third, we'll choose a coordinate system for the :region column. For this service, I'll use the EPSG 3785 projection. This coordinate system is often useful because of its affinity with mapping software, its local conformality, and its ability to keep political boundaries straight. It's also good to choose a flat projection rather than a geographic coordinate system because we're going to do some geometric manipulation. You can read more discussion on choosing a coordinate system for your database in part 7.
Our migration now looks like this:
class CreateZctas < ActiveRecord::Migration
def change
create_table :zctas do |t|
t.integer :zcta
t.polygon :region, :srid => 3785
end
change_table :zctas do |t|
t.index :region, :spatial => true
end
end
end
Now we can run the migration:
% rake db:migrate
As we discussed in part 7, we also set up the ActiveRecord class to use the simple_mercator_factory.
class Zcta < ActiveRecord::Base FACTORY = RGeo::Geographic.simple_mercator_factory set_rgeo_factory_for_column(:region, FACTORY.projection_factory) end
Obtaining ZCTA data and populating our database
A nice feature of ZCTA is that it is public data freely downloadable from the US government. A good start point for exploring the current (2010) Census ZCTA data is http://www.census.gov/geo/ZCTA/zcta.html. If you want to go straight to the downloads, head over here and choose "Zip Code Tabulation Areas" from the menu. You can download shapefiles for individual states, or the entire database as one huge shapefile. (Warning: the combined shapefile download is half a gigabyte compressed.)
For this example, we'll download just the state of Washington, but it should be trivial to modify the code to deal with the entire database. When you download the data for Washington, you'll end up with a zip file "tl_2010_53_zcta510.zip". Unzipping this file yields a set of five files:
- tl_2010_53_zcta510.dbf
- tl_2010_53_zcta510.prj
- tl_2010_53_zcta510.shp
- tl_2010_53_zcta510.shp.xml
- tl_2010_53_zcta510.shx
The .shp extension clues us in that this is a shapefile, one of the formats we covered in part 5. Shapefiles are a very common format for public data sets. They're great for downloading data, but not for running spatial searches. So our next task is to import the shapefile into our database.
The shapefile specifies that its geometric information is in the "NAD83" geographic coordinate system (EPSG 4269). This is a geographic (latitude-longitude) coordinate system optimized for the United States. It does have very slight differences from the WGS84-based coordinate system (EPSG 4326) that we usually use, but for our purposes, the differences are negligible, so we'll treat these as standard WGS84 geographic coordinates.
Now, our database uses the EPSG 3785 projection, so we'll need to convert the polygons into the projection. We covered how to use the simple_mercator_factory to perform these projections in part 7. As we saw in part 4, converting lines and polygons between coordinate systems can change their shape if individual sides are long enough. For our purpose, ZCTA areas are small enough that we'll ignore the effect.
One more issue is that the geometries we'll read from the shapefile are actually MultiPolygons rather than Polygons. This is because some ZCTAs (such as those that cover islands) may include multiple disjoint areas. Since we defined our database column to store polygons, we'll have to break up each MultiPolygon into its constituent parts. This means we may have some ZCTA numbers that are represented by multiple records in the database.
For the ZCTA number, we'll take a quick peek at the Census-provided documentation at http://www.census.gov/geo/www/tiger/tgrshp2010/documentation.html. Here it states that the ZCTA number can be found in the "ZCTA5CE10" property field of each shapefile record.
Now we have enough information to write a script to read the shapefile and populate our database!
require 'rgeo-shapefile'
RGeo::Shapefile::Reader.open('tl_2010_53_zcta510.shp',
:factory => Zcta::FACTORY) do |file|
file.each do |record|
zcta = record['ZCTA5CE10'].to_i
# The record geometry is a MultiPolygon. Iterate
# over its parts.
record.geometry.projection.each do |poly|
Zcta.create(:zcta => zcta, :region => poly)
end
end
end
Let that run for a minute or two, and now we have a fully populated database of ZCTA data for the state of Washington.
Running ZCTA queries
Now let's write a simple API for querying the ZCTA for a given location.
First we'll write some scopes in the ActiveRecord class to construct the queries. To find the ZCTA that contains a particular point location (latitude and longitude), we can use the ST_Intersects function. We just need to make sure we convert the location to the projected coordinate system, as we covered at the end of part 7.
For best performance, we'll write our queries to speak PostGIS's native language, which is EWKB (see part 5).
class Zcta < ActiveRecord::Base
# ...
EWKB = RGeo::WKRep::WKBGenerator.new(:type_format => :ewkb,
:emit_ewkb_srid => true, :hex_format => true)
def self.containing_latlon(lat, lon)
ewkb = EWKB.generate(FACTORY.point(lon, lat).projection)
where("ST_Intersects(region, ST_GeomFromEWKB(E'\\\\x#{ewkb}'))")
end
end
We could also extend this to support queries by any arbitrary geometry, letting us find the ZCTAs that cover a line or polygon:
class Zcta < ActiveRecord::Base
# ...
def self.containing_geom(geom)
ewkb = EWKB.generate(FACTORY.project(geom))
where("ST_Intersects(region, ST_GeomFromEWKB(E'\\\\x#{ewkb)}'))")
end
end
Now it's pretty straightforward to write a web service API wrapper for this function. Here's one way it could be done:
class ZctaController
def lookup
lat = params[:lat].to_f
lon = params[:lon].to_f
zcta = Zcta.containing_latlon(lat, lon).first
render(:json => {:lat => lat, :lon => lon,
:zcta => zcta ? zcta.zcta : nil})
end
end
Segmenting polygons for improved performance
Now that we have a basic implementation, let's see if we can improve performance a bit. In part 6, we saw that large, complex geometries, such as polygons with many sides, can result in slow queries. The ZCTA data, it turns out, does have some fairly large polygons with side counts in the tens of thousands. Since all we're interested in is looking up ZCTA by location, we may be able to improve performance using the segmentation technique.
Segmentation involves breaking up large polygons into smaller polygons with fewer sides. It trades off a smaller polygon size for a larger number of rows in the database. However, the spatial index can help mitigate queries against a large number of rows, so such a trade-off may be a performance win in some situations. (Of course, we should measure so we know for certain---we'll do that below.)
We'll segment using four-to-one subdivision as described in part 6. For each polygon, we'll count its sides, and if the count is larger than some threshold, we'll divide it in half horizontally and vertically. An easy way to accomplish this division is to take the polygon's bounding box and divide it four ways into smaller rectangles. Then, take the intersections of the original polygon with those sub-rectangles. These functions are available in the Simple Features interfaces, and are implemented by RGeo, as we covered in part 3.
Note that it is possible for a subdivision to result in multiple disjoint polygons in each quadrant (that is, a MultiPolygon). So we have to handle that case in the code.
We'll also perform one more optimization: if the polygon is long and thin, we'll divide it in two rather than in four, in order to make the pieces closer to square.
Ready? Here's our implementation:
MAX_SIZE = 500
MAX_DEPTH = 12
require 'rgeo-shapefile'
# Handle a geometry of any type
def handle_geometry(depth, geom, zcta)
case geom
when ::RGeo::Feature::Polygon
handle_polygon(depth, geom, zcta)
when ::RGeo::Feature::MultiPolygon
geom.each{ |polygon| handle_polygon(depth, polygon, zcta) }
end
end
# Handle a polygon
def handle_polygon(depth, polygon, zcta)
# Check the number of sides. We'll combine the number of sides for
# the "outer edge" and any "holes" that the polygon might have.
# A polygon boundary consists of a LineString that is closed, so
# the first and last points are the same. Therefore, to count the
# sides, count the number of vertices and subtract 1.
sides = polygon.exterior_ring.num_points - 1
polygon.interior_rings.each{ |ring| sides += ring.num_points - 1 }
if depth >= MAX_DEPTH || sides <= MAX_SIZE
# The polygon is small enough, or we recursed as far as we're
# willing. Just add the polygon.
Zcta.create(:zcta => zcta, :region => polygon)
else
# Split the polygon 4-to-1 and recurse
depth = depth + 1
# Find the bounding box for the polygon
envelope = polygon.envelope.exterior_ring
p1 = envelope.point_n(0)
p2 = envelope.point_n(2)
min_x = p1.x
max_x = p2.x
min_x, max_x = max_x, min_x if min_x > max_x
min_y = p1.y
max_y = p2.y
min_y, max_y = max_y, min_y if min_y > max_y
# dx and dy are the size of the bounding box.
# cx and cy are the center point.
dx = max_x - min_x
dy = max_y - min_y
cx = (min_x + max_x) * 0.5
cy = (min_y + max_y) * 0.5
# Check the aspect ratio of the bounding box. If it's very wide
# or very tall, then only split in half. Otherwise, split in 4.
if dy > dx * 2
# The bounding box is tall, so split in half
handle_quadrant(depth, polygon, min_x, min_y, max_x, cy, zcta)
handle_quadrant(depth, polygon, min_x, cy, max_x, max_y, zcta)
elsif dx > dy * 2
# The bounding box is wide, so split in half
handle_quadrant(depth, polygon, min_x, min_y, cx, max_y, zcta)
handle_quadrant(depth, polygon, cx, min_y, max_x, max_y, zcta)
else
# The bounding box is close to square so split in four
handle_quadrant(depth, polygon, min_x, min_y, cx, cy, zcta)
handle_quadrant(depth, polygon, cx, min_y, max_x, cy, zcta)
handle_quadrant(depth, polygon, min_x, cy, cx, max_y, zcta)
handle_quadrant(depth, polygon, cx, cy, max_x, max_y, zcta)
end
end
end
# Take a polygon and a box. Run the algorithm on the part of the
# polygon that falls within the box.
def handle_quadrant(depth, polygon, min_x, min_y, max_x, max_y, zcta)
# We do this by creating a rectangle for the box, and computing
# the intersection with the input polygon. The result could be a
# polygon, a MultiPolygon, or an empty geometry.
factory = Zcta::FACTORY.projection_factory
box = factory.polygon(factory.linear_ring([
factory.point(min_x, min_y),
factory.point(min_x, max_y),
factory.point(max_x, max_y),
factory.point(max_x, min_y)]))
handle_geometry(depth, polygon.intersection(box), zcta)
end
# The main shapefile reader.
RGeo::Shapefile::Reader.open('tl_2010_53_zcta510.shp',
:factory => Zcta::FACTORY) do |file|
file.each do |record|
# For each MultiPolygon, analyze it and add to the database
handle_geometry(0, record.geometry.projection,
record['ZCTA5CE10'].to_i)
end
end
Now whenever we consider an optimization, we have to measure its effect. Does it actually work? And if it does, what value of MAX_SIZE should we use?
To find out, I ran the segmentation on the Washington state ZCTA data with different values of MAX_SIZE, and then ran a simple benchmark on each segmentation. The benchmark consisted of 50000 queries randomly distributed across the state. I timed the results on my laptop (an early 2011 Macbook Pro running OSX 10.6.8, Ruby 1.9.2, PostgreSQL 9.0.6, and PostGIS 1.5.3).
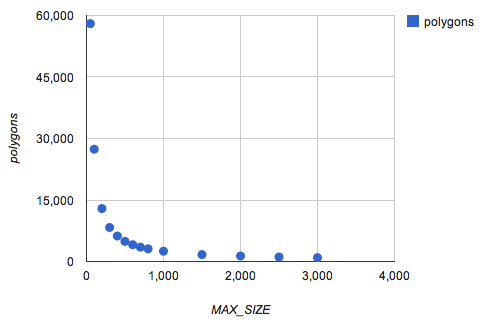
This first graph shows the total number of polygons (database rows) created by the segmentation process, plotted against the MAX_SIZE parameter. The original database had 622 polygons, with a maximum of 9893 sides. As our threshold on the number of sides approaches the low hundreds and smaller, the number of polygons (and hence the number of rows in the database) gets very large.
This second graph shows the total time taken by 50,000 queries against the segmented database, plotted against the MAX_SIZE parameter. The benchmark against the original database took 18.15 seconds. As we can see, decreasing the size of each polygon (by running more subdivisions) improves our query performance up to a point, where the larger number of rows becomes significant.
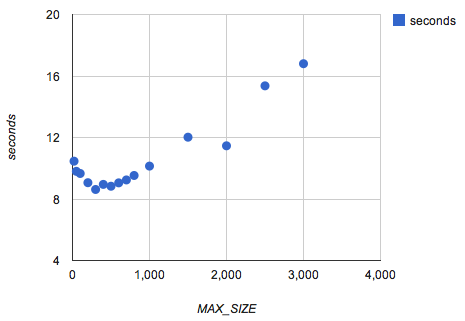
The sweet spot seems to be around the 300-500 side range. At that point, our optimization has cut average query times roughly in half. When I segmented the entire US database of ZCTAs for Pirq, we set MAX_SIZE to 500.
A more difficult question is, is the benefit we measured worth the extra complexity introduced by segmenting? That will depend. At Pirq, we sometimes run these queries in an inner loop, so every optimization matters. We also loaded a few much larger polygons, for which the segmentation procedure had a much more dramatic effect. So for our application, we determined that it was worth it. However, as with all benchmarking, it's important to do your own measurements for your application.
Where to go from here
This article concludes my original outline for this series on geospatial development with Rails. But not to worry---it's not the end. There's still plenty of material to cover and plenty of discussion to be had. I just don't have the next few parts already planned out yet. So this is your chance to direct where this series goes from here. If you have a topic you'd like covered, leave me a comment!
That said, there are a couple of major topics that I haven't yet covered.
- I've covered vector data (i.e. points, lines, and polygons) but not raster data (i.e. image overlays). This is for several reasons. First, raster support in PostGIS is relatively new and not yet that mature. (In fact, unless you are using prereleases of PostGIS 2.0, you have to install another third-party library for raster support.) Second, the Ruby tools, notably RGeo, don't yet support raster data either. And third, you may have noticed that a major theme of these first eight articles has been understanding coordinate systems and projections. This is critical background knowledge for handling raster data, so I though it was important to cover it first.
- I haven't covered much on visualization tools. This is largely because my own work has been largely focused on the back-end, so I don't yet have a lot to contribute on the view side.
I will write something on those topics in the future, but I'm not sure when I'll get to the point where I have enough useful material. In the meantime, the floor is open for other topics!
For now I'll conclude with links to resources on the tools that we've been working with during these articles.
PostGIS is the open source geospatial database of choice. It is an add-on library to the venerable PostgreSQL open source database. For more information on PostGIS, see the documentation online, and sign up for the postgis-users mailing list.
RGeo provides the core geospatial vector data types for Ruby. It is installed as the gem "rgeo". For more information on RGeo, see the documentation online, report issues and contribute to the source at Github, and sign up for the rgeo-users mailing list.
We have also covered several other ruby gems that are used for more specialized tasks. These include:
- rgeo-shapefile (reading ESRI shapefiles). documentation / issues / source
- rgeo-geojson (reading and writing GeoJSON). documentation / issues / source
- activerecord-postgis-adapter (ActiveRecord adapter for PostGIS). documentation / issues / source
There are, of course, many other ruby libraries for other related tasks such as geocoding. Some of these will likely be the subject of future articles.
Finally, I started a mailing list for general geospatial rails discussion, the "georails" google group. Sign up if you're interested in more community discussion.
This is part 8 of my continuing series of articles on geospatial programming in Ruby and Rails. For a list of the other installments, please visit http://daniel-azuma.com/articles/georails.